


如何在 ADI DSP 中设计一个合理的混响 (上)

《如何在 ADI DSP 中设计一个合理的混响》系列专辑由两篇文章构成,围绕着混响的需求、原理以及实现流程展开了详细描述。一方面可以帮助大家了解混响效果的一些基本知识,另一方面工程师可以参考这些模型用到自己的产品上,从而设计出比较贴合自身产品的算法。
本文《如何在 ADI DSP 中设计一个合理的混响 (上) 》分享了混响的类型、主要几大类 DSP 混响的实现原理。在下一篇《如何在 ADI DSP 中设计一个合理的混响 (下) 》中,将对混响的具体参数调整以及选择 ADI DSP 设计合理算法进行深入解析。
DSP 混响的需求来源
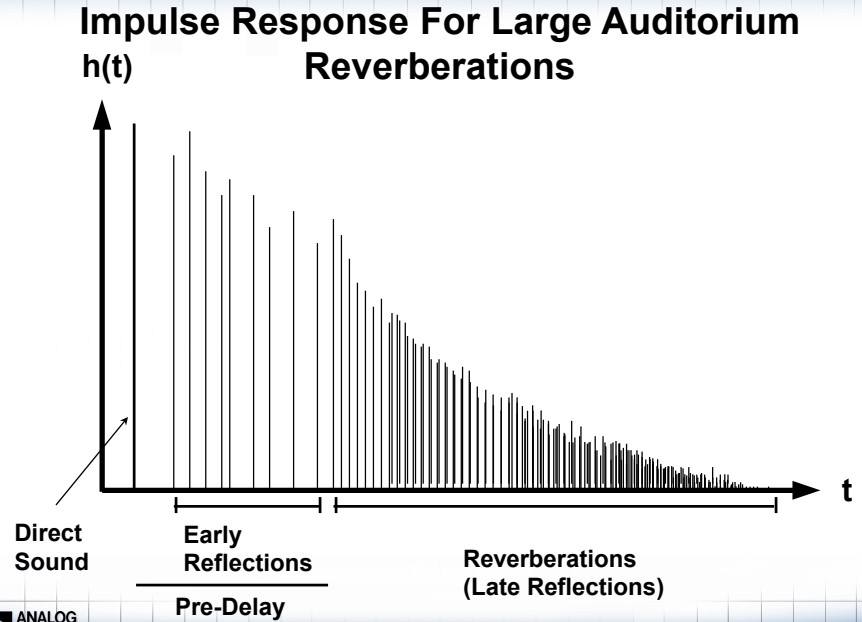
声波在室内传播时,会被墙壁、天花板、地板等障碍物反射,每经过反射一次都会被障碍物吸收一些。当声源停止发声后,声波在室内要经过多次反射和吸收,最后才消失。因此我们可以感觉到,当声源停止发声后还有若干个声波混合持续一段时间,即室内声源停止发声后仍然存在的声延续现象,这种现象叫做混响,这段时间叫做混响时间。
在演奏表演时,为了获取一个高质量的音乐效果,混响是极为重要的组成部分。随着目前声学相关设备的需求量越来越高,大家对音乐中的声音质感要求也越来越高。在混响上主要的实现方式包括物理模拟、采样混响以及人工混响三种方式,物理模拟因为计算量巨大,在实际场景落地比较困难,用的极少。采样混响实现简单,但是灵活度不够,种类也比较少。而人工混响计算量小、实现简单,所以在实际应用上比较广泛,当然缺点就是不如前两种逼真,但是支持普通的调音、混音、演奏需求是完全没有问题的。下面将介绍混响在 DSP 中的概念、应用及其实现。
DSP 混响的定义及优点
DSP 混响 (Digital Signal Processing Reverb) 是一种使用数字信号处理技术 (DSP) 来实现混响效果的技术。混响是指声波在室内或其他封闭空间内反射、散射和衰减的现象,它可以使声音更具空间感、深度和宽度。在音频处理和音乐制作中,混响效果非常重要,它可以让声音更加自然、丰富和立体。它具有以下几种优点:
- 灵活性:可轻松调整改变混响参数,如延迟时间、衰减率、房间大小等,适应不同应用场景。
- 实时处理:通过实时处理技术,对音频信号进行实时处理,从而实现混响效果。
- 高质量:可提供高质量的混响效果,使声音更加自然和真实。
- 节省资源:可节省宝贵的音频处理资源,如CPU、内存等。
总之,DSP 混响在音乐制作、录音、广播、游戏、电影等领域有着广泛的应用,通过 DSP 混响技术,我们可以创造出更加丰富、立体和自然的声音效果。 说到混响,我们还需要知道的一个概念就是回声。回声是在一个方向的延迟反射,而混响则是在多个方向的多次延迟反射。在软件混响原理中我们能看到的基本上分为以下三种类型:
- 回声类:以多回声构建的 echos 系统,回声数量由自身根据具体类型进行控制。
- 脉冲响应类 (IR 类):多见于现场采集各种模型,通过与后音源做卷积来得到较好的输出效果。
- Schroeder & Moorer 类:它是一种混合模型结构。
对于目前市面上主流的一些混响种类,比如房间混响、大厅混响、板式混响、教堂混响、弹簧混响等等,其实现原理都可以用上面三类方式来进行实现。目前我们常见这些混响种类,在调音师或者混音师的工程里,主要用于提升特殊效果,增加音乐的氛围感、空间感和立体感。
ECHO 类混响系统
谈及回声类混响系统,这里不得不提到 Comb Filter 混响器,简单理解就是声音在空间中不断碰撞并产生回声的一个过程。同理,在播放器端,我们需要播放的其实就是一个音源,以及它被无数次后续回声追加的一个过程,简称梳状滤波混响器。这里我们需要建立一个数学模型,下图 (图1) 为一个简单的房间混响模型表示:
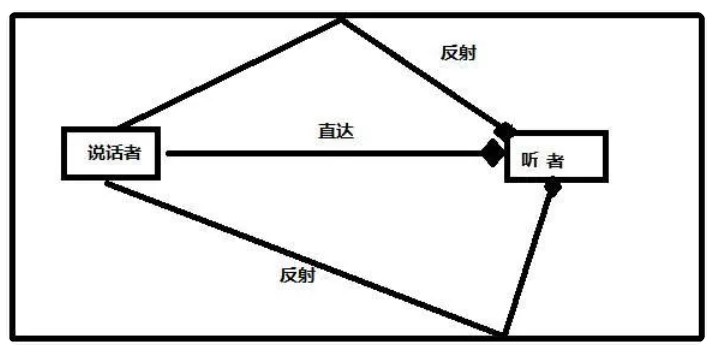
从上图可以看出,房子的反射效果受房间大小以及反射强度影响。如果房间足够大、吸音材料非常好,就会导致房间内基本上没什么反射。反之反射就会比较强烈。在房间建筑学设计中,比较多通过塞宾公式来进行估算,而混响强度的标准一般以 RT60 为主。参考该物理模型,我们在梳妆滤波器的设计过程中就可以进行一系列的公式推导,例如:
假设说话者说出的信号是 x[n],听者某时刻接收到的信号是 y[n],那么 y[n] 包含那些内容呢?
y[n] 应该是 x[n] + 反射 1 + 反射 2 .......
反射怎么表示?它应该是 x[n] 的延时。我们假设延时 m,那么反射 1 应该是 x[n-m],但是我们还应该考虑反射时的衰减,也就是上面所说的房子的反射效果。假设衰减是 a,则反射 1 应该表示成 x[n-m]*a
所以,y[n] = x[n] + a*x[n -m] + a^2*x[n - 2m] + a^3*x[n - 3m] ......
简化下求和,利用差分或者 z 变化可以得到差分方程:y[n] = ay[n - m] + x[n]
通过以上公式推导,可以得到如下图 (图2) 所示的该模型结构图以及时域和频域表现:
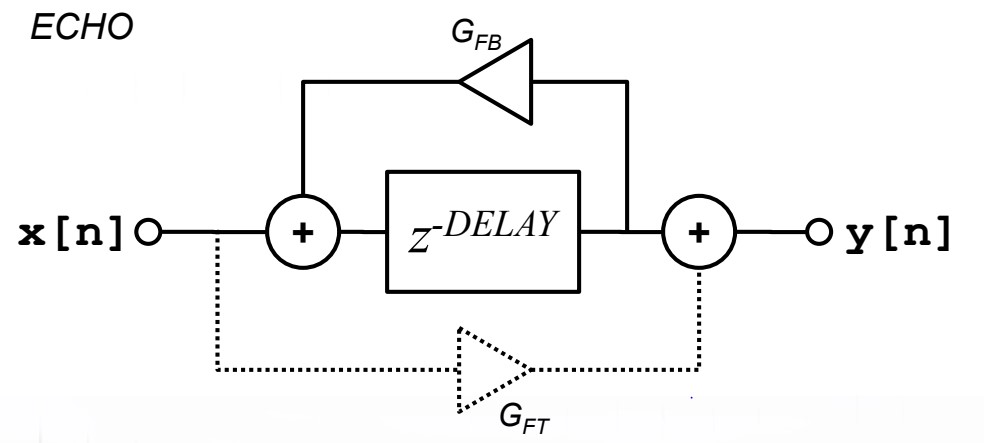
在时域上,作为一个等比例 (反馈衰减系数取决于自身设计的衰减公式) 衰减模型,其呈现一种周期性递减规律,如下图 (图3) 所示:

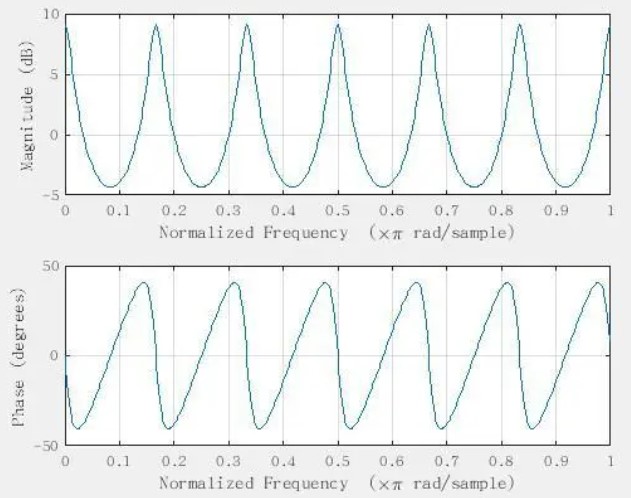
在频域上,系统对频率具有周期响应,且具备最大值与最小值,这样我们将会得到像梳子一样的波形图,如下图 (图4) 所示,因此也被称为梳状滤波器。
由此我们就可以根据这样的模型去设计一个简单的算法,在 DSP 芯片中,它的算力不是很高,存储空间不是很大,但有时候在需要选取一点点回声类混响系统里比较好用的产品时,例如一些轻量级的低功耗电子产品,需要有一点混响的镶边效果,我们就可以用这种方式去实现。而对于另外那些较高标准、功耗不敏感的产品,我们使用以下介绍的两种方式实现效果将会更好。
IR 类混响系统
对于模拟现实生活的中混响,试想一下,如果我们在一个房间里面对面地交谈,因为声音在房间里面的反射是无处不在的,在开始交谈的过程中,会有最开始的一部分直达声进入我们的耳朵,这时它的能量是最高的。随后通过各种各样的反射,声音的能量得到衰减后慢慢进入到我们的耳朵,这个时间和能量的表现就像是一个个脉冲,所以在这里描述它就是脉冲响应类的其中一种混响。那么在实现上,如何达到这种接近现实的混响效果呢?
在计算机领域里,我们很多时候是根据不同的混响特征来生成 IR 文件,也可以根据录制等方式去获取特定的空间混响。因为有一些混响,在算法的实现上十分困难,且具备一定的特异条件,但是当我们又需要到这种混响背景的时候就需要用到它了。在实现上,我们通常通过特定的 IR 文件和原始音源来进行卷积运算,而卷积的计算公式和方式比较复杂,为了方便大家理解,可以想象是把输入的信号和 IR 进行乘法运算,从而达到使输入的信号里面有 IR 的混响效果。
在 DSP 的实现上,类比我们经常能够在一些上位机软件中看到的特征混响,这些 IR 文件将以各种方式存储在我们的 Flash 内,并且可能具备多个 model 1、model 2、model 3 等等。取特定文件出来,在 DSP 内部进行卷积运算输出即可,这多见于一些音乐设备中特定类型的混响。
Schroeder & Moorer 类混响系统
上文提及的 ECHO 类混响,在梳状滤波器设计完毕后,会存在一些不完美的地方。其实从幅度谱以及相位谱就能看出来,幅度谱不是足够平坦,这样在共振峰和瞬态比较大的条件下,它所带来的声音表现着色非常严重,相位的变化也不恒定。因此 Schroeder 对混响进行了大量的改良技术,在“Colorless” Artificial Reverberation – 1961 和 Natural Sounding Artificial Reverberation – 1962 的两篇论文中有提到该技术。
针对回波密度不够的表现,增加了多组梳状滤波器的并联组合,同时加入了全通滤波器。因为全通滤波器的频谱就是一条直线,不对任何频率产生影响,且仅仅只是附带一些群延时的效果,这样就可以用来实现消除强烈着色的效果。同时因为回声密度的增加,将使得系统更加趋近于真实的效果,如下图 (图5) 所示:
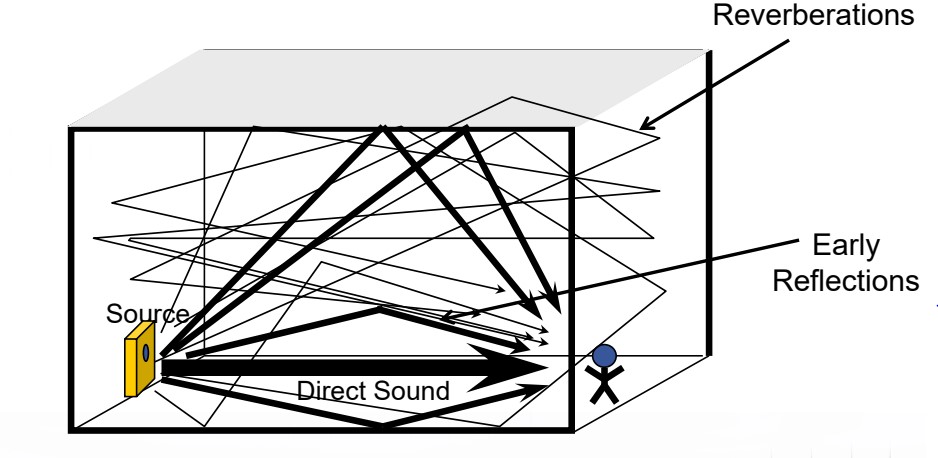
其脉冲响应大概可以描述成如下图 (图6) 所示的图形:
下图 (图7) 为其模型块状图:
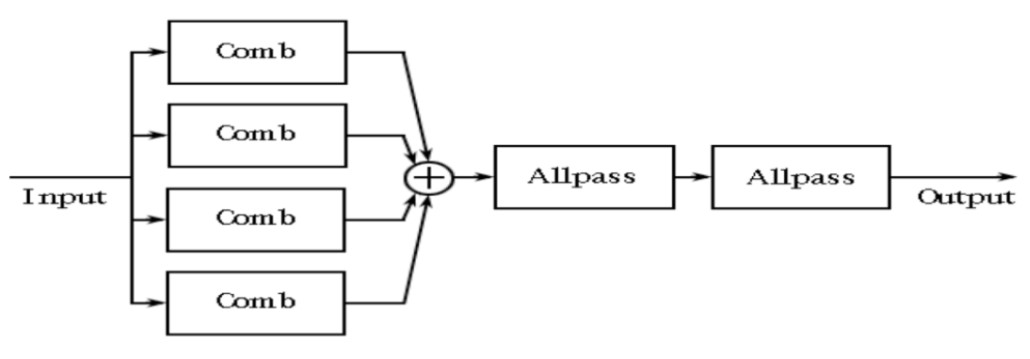
从上图模型不难看出,4 个梳状滤波器的叠加会使我们大大增加回声密度,从而弥补了 ECHO 类回声密度过于稀少的问题。在 Schroeder 的观念里,每秒的回声至少要达到 1000 个才能基本符合,且每个回声的延迟不能一样,一样就会导致 4 个梳状滤波器制造的回声时域上的一致,这样就失去其意义。做完梳状滤波器的叠加后,通过连接 2 个全通滤波器做乘法运算,在进一步增加回声密度的同时减少金属音。
在 Comb 的参数选择上,延时的比例一般选在 1:1.5,尽量选择没有公因数的延迟时间,有公因数会导致某些地方的重叠,并且合理地设计好 G (衰减系数) 的大小,一般都是根据 D 值和 RT60 进行计算,确保大小是在一个比较合理的范围。在全通滤波器的选择上,延时尽可能要低 (1-5ms),增益值在 0.5-0.77 之间会比较合适。
Schroeder 混响的算法相对而言比较简单,而且也能达到一个非常不错的效果。但是随着后来的发展,Schroeder 算法也存在一些可以改进的点,例如上图 (图6) 的预梳理和预延时模块,如果想获取更加逼真的效果,在早期反射其实不能够完全按照 Schroeder 模型进行设计,要增加 APF 以及 Pre-delay 模块,或者考虑是否可以增加更加多的 Comb 来获取更多的回声密度、后端的 APF 是否可以嵌套使用等等。在 Schroeder 的基础之上,Moorer 的数字混响模型也就诞生了,下图 (图8) 为 Moorer 脉冲响应模型图:
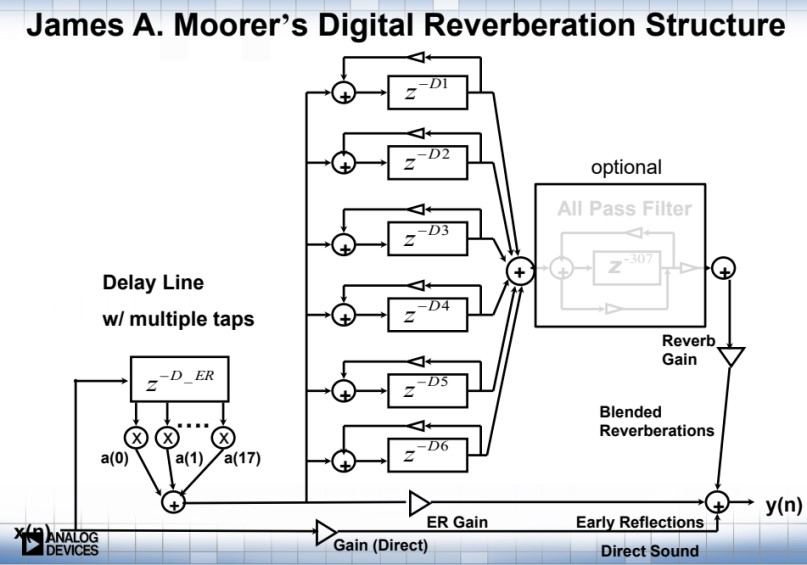
Moorer 算法模型大概将一个混响分成了三个阶段:直达声、早期混响和晚期混响。早期混响通过增加前级反馈和 FIR 来模拟,同时增加低通滤波器来模拟高通在空气的衰减效果,后端增加到 6 个 Comb 组以及 APF 的嵌套使用。
随着目前大家对音频相关产品的需求增加,混响对于音频设备来说已经成为一种基本需求。那么在混响中又有哪些参数调整?在 ADI DSP 中我们该如何选择 DSP 去设计一套合理的算法?这些内容将会在《如何在 ADI DSP 中设计一个合理的混响 (下) 》为大家介绍。
总结
本文主要分析了混响的类型、主要几大类 DSP 混响的实现原理,工程师们可以根据自己的实际情况来合理设计自己的混响算法。欲了解更多技术细节和 ADI 相关方案,您可以点击下方「联系我们」,提交您的需求,我们骏龙科技公司愿意为您提供更详细的技术解答。
相关阅读